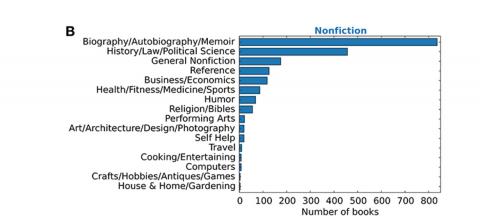
Data scientist Albert-Lázló Barabási analysed the sales patterns of 4,493 fiction and non-fiction books that made the New York Times bestseller list for hardcovers over thee last decade. The findings show the most popular categories of fiction and non-fiction books, that most book sell the most in their first week and that new-comers are best placed for success with book launches in February of March.
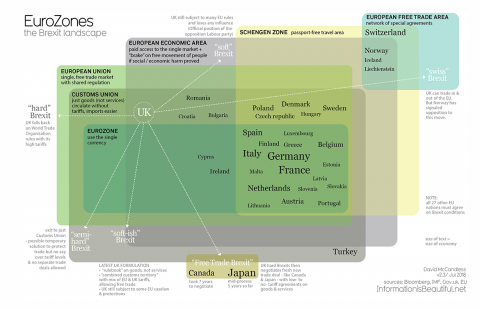
Another great visualisation from Information Is Beautiful. This can be considered "a living document" given the amount of flux in the Brexit position at the moment! :-p
Learning Dollars have put together a great list of 15 source code tools that can be used to help developers make sense of professional code bases, ranging from Chrome Developer Tools up to research projects to illustrate runtime events based on questions asked by the user.
The Information Is Beautiful Awards have released thie year's shortlists in categories such as Humanitarian, Breaking News, Leisure, Games & Sport and Visualization & Information Design, among others. Go inhale the data visualisation goodness on their site.
Australian software engineer Sarah Spencer hacked a 1980's knitting machine to create a massive equatorial star map, with the plan to exhibit it at the Electromagnetic Field Camp festival on Aug 31st, 2018. As a result, the star map is aligned with the night sky on the date of the festival!
I recently re-discovered The Pudding, a fantastic datavis site that uses visual essays to explain cultural ideas, such as the proliferations of repetitive pop lyrics and hip-hop vocabulary, a visual history of every Air Jordan and gender parity in the U.S. and U.K. governments.
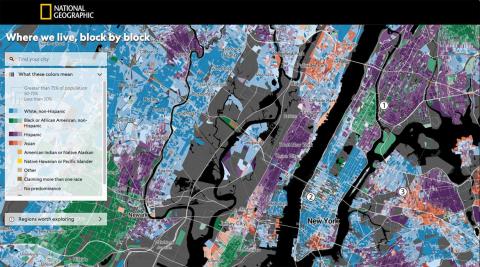
National Geographic have produced a fascinating interactive map of America showing the ethnicity of each block based on 2010 census data. It is part of their series Diversity In America.
Noah Veltman of Netflix has produced this nice data visualisation of how different news websites layout and priorise their editorial, ads and sponsored content.
Google have launched a search engine for data sets similar to Google Scholar, allowing data scientists, researchers and others. The search engine presents summaries of each dataset along with links to the source location of the dataset.